SHOW DATABASES;
CREATE DATABASE nomdelabase;
CREATE DATABASE IF NOT EXISTS nomdelabase;
USE nomdelabase;
DROP DATABASE nomdelabase;
CREATE TABLE utilisateur (
id INTEGER NOT NULL AUTO_INCREMENT PRIMARY KEY,
nom VARCHAR(100),
prenom VARCHAR(100),
email VARCHAR(255) NOT NULL UNIQUE
);
id INTEGER NOT NULL AUTO_INCREMENT PRIMARY KEY,
nom VARCHAR(100),
prenom VARCHAR(100),
email VARCHAR(255) NOT NULL UNIQUE
);
ou
CREATE TABLE IF NOT EXISTS utilisateur;
Voici un tableau récapitulatif du schéma des utilisateurs :| Nom du champ | Type du champ et options | Description |
|---|---|---|
| id | PRIMARY KEY (option) | Champ spécial obligatoire dans toutes les tables. Indique à MySQL que ce champ sera l'identifiant permettant d'identifier les objets. |
| INTEGER (type) | Champ numérique sous forme de nombre entier. | |
| NOT NULL (option) | Ce champ ne peut pas être nul. | |
| AUTO_INCREMENT (option) | Ce champ sera créé par MySQL automatiquement, pas besoin de s'en soucier ! MySQL va utiliser l'id précédent et y ajouter +1 lors de l'ajout d'un nouvel objet. |
|
| nom | VARCHAR(100) (type) | Champ sous forme de texte, limité à 100 caractères. |
| prenom | VARCHAR(100) (type) | Champ sous forme de texte, limité à 100 caractères. |
| VARCHAR(255) (type) | Champ sous forme de texte, limité à 255 caractères. |
|
| NOT NULL (option) | Ce champ ne peut pas être nul. | |
| UNIQUE (option) | Ce champ ne peut pas avoir la même valeur en double. |
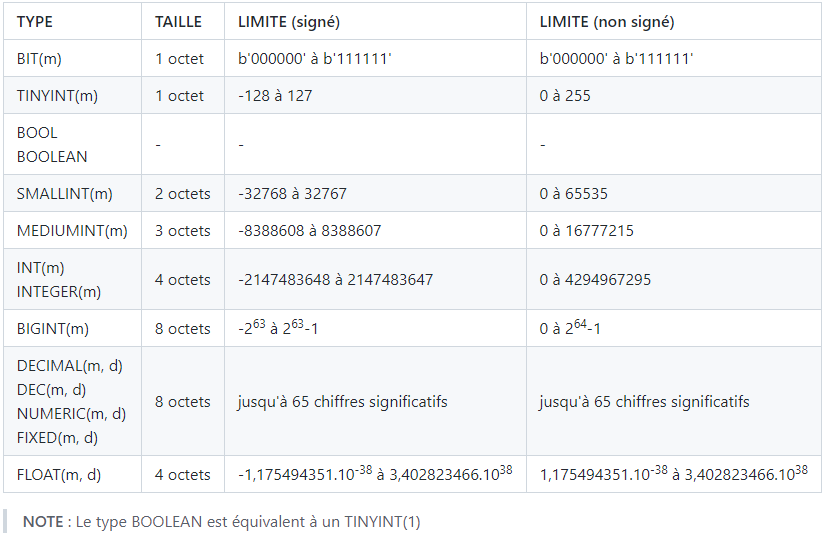
- Types de données
- Types numeriques
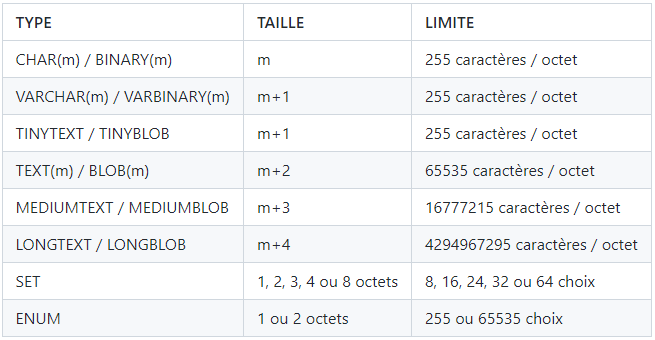
- Types pour les chaînes
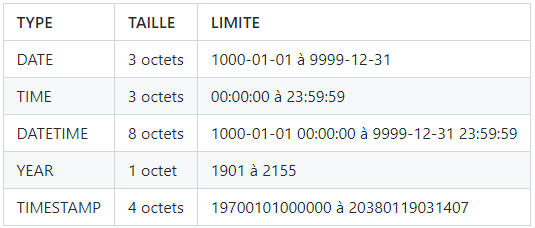
- Types pour les dates
- Proprietes disponibles
- FLOAT
signifie que le champ contiendra des chiffres décimaux ; - BOOLEAN
est un type de champ très connu en informatique.
Il ne peut stocker que les valeurs true (vrai) ou false (faux) ; - DEFAULT
sert à indiquer une valeur par défaut.
Utile pour ne pas avoir à spécifier une valeur tout le temps !
Ici, on indique que la valeur par défaut sera la valeur false .
SHOW tables;
describe nomdelatable;
ALTER TABLE utilisateur
ADD COLUMN langue VARCHAR(100) NOT NULL;
ADD COLUMN langue VARCHAR(100) NOT NULL;
ALTER TABLE utilisateur
DROP langue;
DROP langue;
ALTER TABLE langue
CHANGE nom nom_langue VARCHAR(10) NOT NULL;
CHANGE nom nom_langue VARCHAR(10) NOT NULL;
C’est une spécificité propre à MySQL : pour renommer une colonne, il faut aussi indiquer son type.
Ce qui n’est pas nécessaire si vous utilisez un autre SGBD.
Cela permet de modifier à la fois le nom et le type d’une colonne dans une seule commande.
Et ce, même si vous ne souhaitez pas le modifier(réutilisez alors le même type)
ALTER TABLE langue
MODIFY nom VARCHAR(250) NOT NULL;
MODIFY nom VARCHAR(250) NOT NULL;
SHOW COLUMNS FROM utilisateur;
INSERT INTO `utilisateur` (`nom`, `prenom`, `email`)
VALUES
('Durantay', 'Quentin', 'quentin@gmail.com');
VALUES
('Durantay', 'Quentin', 'quentin@gmail.com');
INSERT INTO `utilisateur` (`nom`, `prenom`, `email`)
VALUES
('Doe', 'John', 'john@yahoo.fr'),
('Smith', 'Jane', 'jane@hotmail.com'),
('Dupont', 'Sebastien', 'sebastien@orange.fr'),
('Martin', 'Emilie', 'emilie@gmail.com');
VALUES
('Doe', 'John', 'john@yahoo.fr'),
('Smith', 'Jane', 'jane@hotmail.com'),
('Dupont', 'Sebastien', 'sebastien@orange.fr'),
('Martin', 'Emilie', 'emilie@gmail.com');
SELECT * FROM aliment
SELECT `nom`, `prenom`, `email` FROM utilisateur;
UPDATE utilisateur SET `email` = 'quentind@gmail.com' WHERE `id` = '1';
UPDATE utilisateur SET `nom`= 'Pascal', `email` = 'quentind@gmail.com' WHERE `id` = '1';
DELETE FROM utilisateur WHERE `id` = '2';
Utilisation de
WHERE
SELECT * FROM nomdelatable WHERE key = “value”;
Vous pouvez appliquer WHERE à n’importe quelle colonne en utilisant le nom de cette colonne.
À noter que WHERE peut s'exécuter avec SELECT , UPDATE ou DELETE
À noter que WHERE peut s'exécuter avec SELECT , UPDATE ou DELETE
SELECT * FROM nomdelatable WHERE key < value;
Vous pouvez utiliser tous les opérateurs classiques, tels que :
- supérieur à ( > ) ;
- inférieur à ( < ) ;
- supérieur ou égal à (>=) ;
- et inférieur ou égal à (<=).
SELECT * FROM utilisateur WHERE email LIKE “%gmail.com”;
va afficher tous les utilisateurs dont l’e-mail se termine par “gmail.com”.
- Utilisation de "%"
- %gmail.com : Texte se terminant par "gmail.com"
- gmail.com% : Texte commençant par "gmail.com"
- %gmail.com% : Texte contenant "gmail.com" au début ou à la fin
Ce mot clé vous permet d’ordonner une colonne par ordre croissant (ascending en anglais, d’où le mot clé SQL ASC),
ou décroissant (descending en anglais, soit le mot clé DESC).
Afficher les elements par ordre croissant.
SELECT * FROM nomdelatable ORDER BY key ASC;
Afficher que les aliments dont les calories ne dépassent pas 90 kcal, mais de manière décroissante :
SELECT * FROM aliment WHERE calories < 90 ORDER BY calories DESC;
Cette commande fonctionne aussi avec le texte !
Si vous effectuez un ORDER BY sur une colonne de texte, celle-ci sera ordonnée :
- soit dans l’ordre alphabétique ( ASC ).
SELECT * FROM utilisateurs ORDER BY prenom ASC;
affiche les utilisateurs avec les prénoms affichés par ordre alphabétique ; - soit dans l’ordre opposé ( DESC ).
SELECT * FROM utilisateurs ORDER BY prenom DESC;
affiche les utilisateurs avec les prénoms affichés par ordre anti-alphabétique.
SELECT COUNT(*) FROM nomdelatable WHERE key LIKE "value";
En appliquant un COUNT(*) , vous comptez le nombre d’objets.
Mais vous pouvez aussi restreindre le comptage à une colonne spécifique en écrivant COUNT(colonne) .
Enfin, vous pouvez aussi compter le nombre d’éléments uniques d’une colonne avec COUNT(DISTINCT colonne) .
Mais vous pouvez aussi restreindre le comptage à une colonne spécifique en écrivant COUNT(colonne) .
Enfin, vous pouvez aussi compter le nombre d’éléments uniques d’une colonne avec COUNT(DISTINCT colonne) .
Par exemple,SELECT COUNT(*)FROM utilisateur; compte tous les utilisateurs,
tandis que SELECT COUNT(nom) FROM utilisateur; compte tous les noms de famille.
Ok, vous allez me dire qu’on trouve exactement le même nombre. Et c’est vrai.
Compter dans une colonne prend vraiment son sens en comptant le nombre de valeurs distinctes.
SELECT COUNT(DISTINCT nom) FROM utilisateur; comptera uniquement les noms de familles différents, vous permettant de voir si certains utilisateurs ont le même nom !
Envie de connaître le maximum de teneur en sucre des aliments dans notre base ?
Rien de plus simple :
SELECT MAX(sucre) FROM aliment;
Quelle est la teneur moyenne en calories des aliments de 30 kcal ou plus ?
SELECT AVG(calories) FROM aliment WHERE calories >= 30;
- AVG : nous donne la moyenne de la colonne sur la sélection ;
- SUM : nous donne la somme de la colonne sur la sélection ;
- MAX : nous donne le maximum de la colonne sur la sélection ;
- MIN : nous donne le minimum de la colonne sur la sélection.
- Exemple :
-
SELECT COUNT(*) FROM aliment WHERE bio = false;
Compte le nombre d'aliment qui ne sont pas bio -
SELECT MAX(proteines) FROM aliment WHERE bio = false;
Selectionne l'aliment qui a le max de proteine qui n'est pas bio
(et affiche le nombre de proteines) -
SELECT MIN(proteines) FROM aliment WHERE bio = false;
Selectionne l'aliment qui a le moins de proteine qui n'est pas bio
(et affiche le nombre de proteines) -
SELECT AVG(proteines) FROM aliment WHERE bio = false;
Affiche la moyenne de proteines dans les aliments qui ne sont pas bio
(et affiche le nombre de proteines)
Sauvegarder dans une vue la commande suivante : les utilisateurs dont l’adresse mail est une adresse Gmail:
CREATE VIEW utilisateurs_gmail_vw AS SELECT * FROM utilisateur WHERE email LIKE "%gmail.com";
Je viens de créer la vue “utilisateurs_gmail_vw”.
Cette dernière s’utilise désormais comme une table.
Ainsi, pour récupérer les utilisateurs avec une adresse Gmail, plus besoin d’écrire ma requête compliquée !
Je n’ai plus qu’à écrire :
SELECT * FROM utilisateurs_gmail_vw;
La convention chez les utilisateurs de SQL est de toujours préfixer le nom d’une vue avec “_vw”, pour la distinguer des “vraies” tables.
Afficher les utilisateurs dont l’adresse e-mail est une adresse Gmail ET dont le prénom contient la lettre “m” :
SELECT * FROM utilisateurs_gmail_vw WHERE prenom LIKE "%m%";
Créer une vue reprenant notre liste des aliments non bio, classés par contenance en protéines (de manière décroissante).
CREATE VIEW aliments_non_bio_vw AS SELECT * FROM aliment WHERE bio = false ORDER BY proteines DESC;
Relation 1 à plusieurs
Afin de pouvoir s’adapter à chacun, l’application va devoir stocker la langue préférée de chaque utilisateur.
Pour ce faire, la table “langue” a été rajoutée à la base de données.
Chaque utilisateur est relié à une langue.
Et chaque langue peut être reliée à plusieurs utilisateurs.
On parle alors d’une relation 1 à plusieurs entre utilisateur et langue (one-to-many, en anglais).
Pour matérialiser une telle relation dans une base SQL telle que MySQL, on suit un principe assez simple :
- Dans ce cas spécifique, une langue est reliée à plusieurs utilisateurs.
On crée donc cet objet normalement, comme vous avez pu le faire précédemment.
INSERT INTO `langue` VALUES ('français'); - Chaque utilisateur se voyant relié à une langue,
c’est l’utilisateur qui va devoir stocker l’id unique de la langue associée.
Par convention, on utilise comme nom de ce champ {nom de l’objet associé}_id (donc ici, langue_id ).
Par exemple, le premier utilisateur a comme langue_id 1, soit l’id du français dans la table des langues.
Imaginez désormais qu’on vous demande de ressortir toutes les langues utilisées par les 10 premiers utilisateurs, ou tous les utilisateurs ayant configuré Foodly en anglais.
Il existe une commande qui est justement là pour régler ce genre de problème.
La commande JOIN.
La commande JOIN.
Grâce à cette commande, vous allez pouvoir expliquer à MySQL comment joindre deux tables selon un identifiant qu’elles ont en commun.
Partons du principe que :
- la langue_id du premier utilisateur est le français ;
- l’id du français est 1.
Prenons un exemple.
Regardons tous les utilisateurs avec les langues qui leur sont associées.
Tapez cette commande dans votre terminal :
SELECT * FROM `utilisateur`
JOIN `langue`
ON `utilisateur`.`langue_id` = `langue`.`id`;
JOIN `langue`
ON `utilisateur`.`langue_id` = `langue`.`id`;
Que s’est-il passé dans cette commande ?
- Nous avons demandé à MySQL de sélectionner tous les utilisateurs.
SELECT * FROM `utilisateur` - Auxquels nous voulons joindre les langues.
JOIN `langue` - En précisant à MySQL de les relier, en considérant que l’id de la langue est stockée dans chaque utilisateur dans le champ langue_id.
ON `utilisateur`.`langue_id` = `langue`.`id`
Exemple :
Rechercher tous les noms de famille des utilisateurs ayant sélectionné le français.
SELECT * FROM utilisateur
JOIN langue
ON utilisateur.langue_id = langue.id WHERE langue.nom = 'français';
JOIN langue
ON utilisateur.langue_id = langue.id WHERE langue.nom = 'français';
Relation plusieurs à plusieurs
La relation plusieurs à plusieurs permet à chaque objet d’une table de pouvoir être relié à plusieurs objets de l’autre table, et vice versa.